Include dependency graph for Hermite4GPU.cuh:
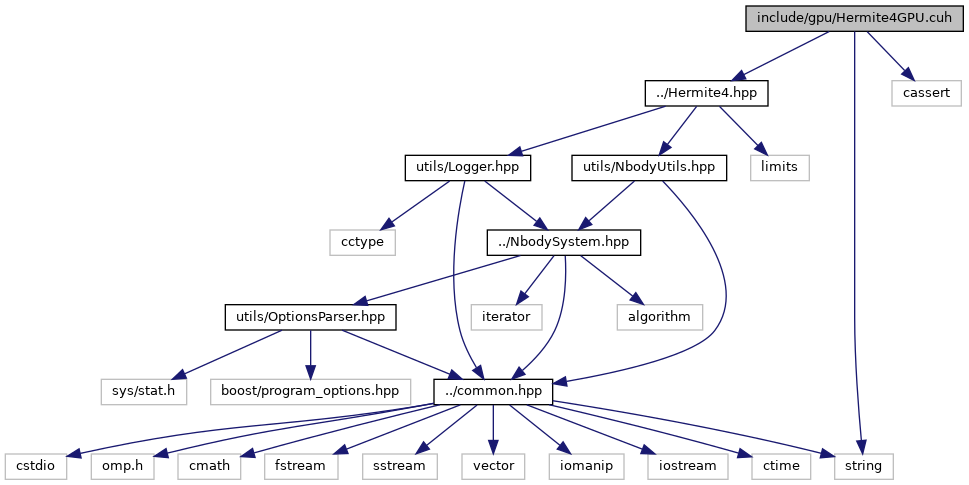
This graph shows which files directly or indirectly include this file:

Classes | |
| class | Hermite4GPU |
| Class which implements on the GPU the structure of the Hermite4 scheme. More... | |
Macros | |
| #define | HERMITE4GPU_HPP |
| #define | CSC_NO_SYNC(call) |
| #define | CSC(call) CSC_NO_SYNC(call); |
Functions | |
| __host__ __device__ double4 | operator+ (const double4 &a, const double4 &b) |
| __host__ __device__ void | operator+= (double4 &a, double4 &b) |
| __host__ __device__ Forces | operator+ (Forces &a, Forces &b) |
| __host__ __device__ void | operator+= (Forces &a, Forces &b) |
| __global__ void | k_init_acc_jrk (Predictor *p, Forces *f, int n, double e2, int dev, int dev_size) |
Initialization kernel, which consider an 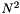 interaction of the particles. More... interaction of the particles. More... | |
| __global__ void | k_prediction (Forces *f, double4 *r, double4 *v, double *t, Predictor *p, int dev_size, double ITIME) |
| Predictor kernel, in charge of performing the prediction step of all the particles on each integration step. More... | |
| __device__ void | k_force_calculation (Predictor i_p, Predictor j_p, Forces &f, double e2) |
| Force interaction kernel, in charge of performing gravitational interaction computation between two particles. More... | |
| __global__ void | k_update (Predictor *i_p, Predictor *j_p, Forces *fout, int n, int total, double e2) |
Force kernel, in charge of performing distribution of how the 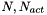 particles will be distributed among the GPUs. More... particles will be distributed among the GPUs. More... | |
| __global__ void | k_reduce (Forces *in, Forces *out, int shift_id, int shift) |
Force reduction kernel, in charge of summing up all the preliminary results of the forces for the 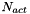 particles. More... particles. More... | |
| __global__ void | k_energy (double4 *r, double4 *v, double *ekin, double *epot, int n, int dev_size, int dev) |
| Energy kernel, in charge of the calculation of the kinetic and potential energy on the GPUs. More... | |
Macro Definition Documentation
§ CSC
| #define CSC | ( | call | ) | CSC_NO_SYNC(call); |
§ CSC_NO_SYNC
| #define CSC_NO_SYNC | ( | call | ) |
Value:
do { \
cudaError err = call; \
if( cudaSuccess != err) { \
fprintf(stderr, "Cuda error in file '%s' in line %i : %s.\n", \
__FILE__, __LINE__, cudaGetErrorString( err) ); \
exit(EXIT_FAILURE); \
} } while (0)
§ HERMITE4GPU_HPP
| #define HERMITE4GPU_HPP |
Function Documentation
§ k_energy()
| __global__ void k_energy | ( | double4 * | r, |
| double4 * | v, | ||
| double * | ekin, | ||
| double * | epot, | ||
| int | n, | ||
| int | dev_size, | ||
| int | dev | ||
| ) |
Energy kernel, in charge of the calculation of the kinetic and potential energy on the GPUs.
§ k_force_calculation()
Force interaction kernel, in charge of performing gravitational interaction computation between two particles.
§ k_init_acc_jrk()
| __global__ void k_init_acc_jrk | ( | Predictor * | p, |
| Forces * | f, | ||
| int | n, | ||
| double | e2, | ||
| int | dev, | ||
| int | dev_size | ||
| ) |
Initialization kernel, which consider an interaction of the particles.
§ k_prediction()
| __global__ void k_prediction | ( | Forces * | f, |
| double4 * | r, | ||
| double4 * | v, | ||
| double * | t, | ||
| Predictor * | p, | ||
| int | dev_size, | ||
| double | ITIME | ||
| ) |
Predictor kernel, in charge of performing the prediction step of all the particles on each integration step.
§ k_reduce()
Force reduction kernel, in charge of summing up all the preliminary results of the forces for the particles.
§ k_update()
| __global__ void k_update | ( | Predictor * | i_p, |
| Predictor * | j_p, | ||
| Forces * | fout, | ||
| int | n, | ||
| int | total, | ||
| double | e2 | ||
| ) |
Force kernel, in charge of performing distribution of how the particles will be distributed among the GPUs.
This kernel calls the k_prediction kernel.
